Scheduling Metaflow Flows with Apache Airflow
Apache Airflow is a popular open-source workflow orchestrator. It has a number of limitations compared to Argo Workflows and AWS Step Functions, so we mainly recommend it if you are an existing Airflow user and you want to avoid introducing a new orchestrator in your environment.
The Metaflow-Airflow integration is a great way to modernize your Airflow deployment. It provides a more user-friendly and productive development API for data scientists and data engineers, without needing to change anything in your existing pipelines or operational playbooks, as described in its announcement blog post. To learn how to deploy and operate the integration, see Using Airflow with Metaflow.
Here are the main benefits of using Metaflow with Airflow:
- You get to use the human-friendly API of Metaflow to define and test workflows.
Almost all features of Metaflow work with Airflow out of the box, except nested
foreaches, which are not supported by Airflow, and
@batchas the current integration only supports@kubernetes. - You can deploy Metaflow flows to your existing Airflow server without having to change anything operationally. From the Airflow's point of view, Metaflow flows look like any other Airflow DAG.
- If you want to consider moving to another orchestrator supported by Metaflow, you can test them easily just by changing one command to deploy to Argo Workflows or AWS Step Functions.
When running on Airflow, Metaflow code works exactly as it does locally: No changes are
required in the code. All data artifacts produced by steps run on Airflow are available
using the Client API. All tasks are run on Kubernetes
respecting the @resources decorator, as if the @kubernetes decorator was added to
all steps, as explained in Executing Tasks
Remotely.
This document describes the basics of Airflow scheduling. If your project involves multiple people, multiple workflows, or it is becoming business-critical, check out the section around coordinating larger Metaflow projects.
Conditional and recursive steps introduced in Metaflow 2.18, are not yet supported on Airflow deployments. Contact the Metaflow Slack if you have a use case for this feature.
Pushing a flow to production
Let's use the flow from the section about parameters as an example:
from metaflow import FlowSpec, Parameter, step
class ParameterFlow(FlowSpec):
alpha = Parameter('alpha',
help='Learning rate',
default=0.01)
@step
def start(self):
print('alpha is %f' % self.alpha)
self.next(self.end)
@step
def end(self):
print('alpha is still %f' % self.alpha)
if __name__ == '__main__':
ParameterFlow()
Save this script to a file parameter_flow.py. To deploy a version to Airflow, simply
run
python parameter_flow.py --with retry airflow create parameter_dag.py
This command takes a snapshot of your code in the working directory, as well as the
version of Metaflow used, and creates an Airflow DAG in parameter_dag.py for
scheduling on Airflow. You should deploy parameter_dag.py to your Airflow instance
like you would do with any other user-written DAG.
Metaflow automatically maps the Parameters of your flow to corresponding parameters on Airflow. You can execute your Metaflow flow deployed on Airflow like any other Airflow DAG - seamlessly getting all the benefits of Airflow alongside all the benefits of Metaflow.
Hardening deployments
It is highly recommended that you enable
retries when deploying
to Airflow, which you can do easily with --with retry as shown above. However, make
sure that all your steps are safe to retry before you do this. If some of your steps
interact with external services in ways that can't tolerate automatic retries, decorate
them with retry with times set to zero (times=0) as described in How to Prevent
Retries.
If you want to test on Airflow without interfering with a production flow, you can
change the name of your class, e.g. from ParameterFlow to ParameterFlowStaging, and
airflow create the dag under a new name or use the @project
decorator.
Note that airflow create creates a new isolated production namespace for your production flow. Read Organizing Results to learn all about namespace behavior.
Limiting the number of concurrent tasks
By default, Metaflow configures Airflow to execute at most 100 tasks concurrently within a foreach step. This should ensure that most workflows finish quickly without overwhelming your Kubernetes cluster, the execution backend.
If your workflow includes a large foreach and you need results faster, you can increase
the default with the --max-workers option. For instance, airflow create --max-workers
500 allows 500 tasks to be executed concurrently for every foreach step.
This option is similar to run
--max-workers that is used to
limit concurrency outside Airflow.
Deploy-time parameters
You can customize Airflow deployments through Parameters that are evaluated at the
deployment time, i.e. when airflow create is executed.
For instance, you can change the default value of a Parameter based on who deployed
the workflow or what Git branch the deployment was executed in. Crucially, the function
in Parameter is evaluated only once during airflow create and not during the execution
of the flow.
You can run the flow locally as usual. The function inside Parameter is called only
once when the execution starts.
from metaflow import FlowSpec, Parameter, step, JSONType
from datetime import datetime
import json
def deployment_info(context):
return json.dumps({'who': context.user_name,
'when': datetime.now().isoformat()})
class DeploymentInfoFlow(FlowSpec):
info = Parameter('deployment_info',
type=JSONType,
default=deployment_info)
@step
def start(self):
print('This flow was deployed at %s by %s'\
% (self.info['when'], self.info['who']))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
DeploymentInfoFlow()
When airflow create is called, deployment_info is evaluated which captures your
username and the time of deployment. This information remains constant on Airflow
Workflows, although the user may override the default value.
The context object is passed to any function defined in Parameter. It contains various
fields related to the flow being deployed. By relying on the values passed in context,
you can create generic deploy-time functions that can be reused by multiple flows.
Scheduling a flow
By default, a flow on Airflow does not run automatically. You need to set up a trigger to launch the flow when an event occurs.
On Airflow, Metaflow provides built-in support for triggering Metaflow flows through time-based (cron) triggers, which, as the name implies, triggers the workflow at a certain time. As of today, [event-based triggering] (/production/event-triggering) is not supported on Airflow.
Time-based triggers are implemented at the FlowSpec-level using the @schedule
decorator. This flow is triggered hourly:
from metaflow import FlowSpec, schedule, step
from datetime import datetime
@schedule(hourly=True)
class HourlyFlow(FlowSpec):
@step
def start(self):
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('time is %s' % now)
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
HourlyFlow()
You can define the schedule with @schedule in one of the following ways:
@schedule(weekly=True)runs the workflow on Sundays at midnight.@schedule(daily=True)runs the workflow every day at midnight.@schedule(hourly=True)runs the workflow every hour.@schedule(cron='0 10 * * ? *')runs the workflow at the given Cron schedule, in this case at 10am UTC every day.
Reproducing failed production runs
Let's use DebugFlow from the debugging
section as an example. The flow
contains a bug in the step b. When you run it, the failed run will look like this on
the Airflow UI:
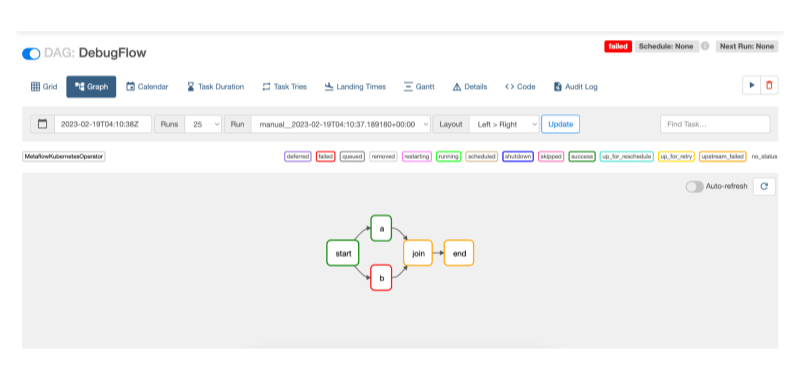
The graph visualization shows that step b failed, as expected. First, you should inspect the logs of the failed step in the Airflow UI (or the Metaflow UI) to get an idea of why it failed.
Notice the Metaflow Run ID of airflow-ec19e85042a1 that is available from the Rendered
Template page for the failed task in the Airflow UI (look for the metaflow_run_id
attribute). You can use this Run ID to locate the execution in the Metaflow UI as well
if needed.
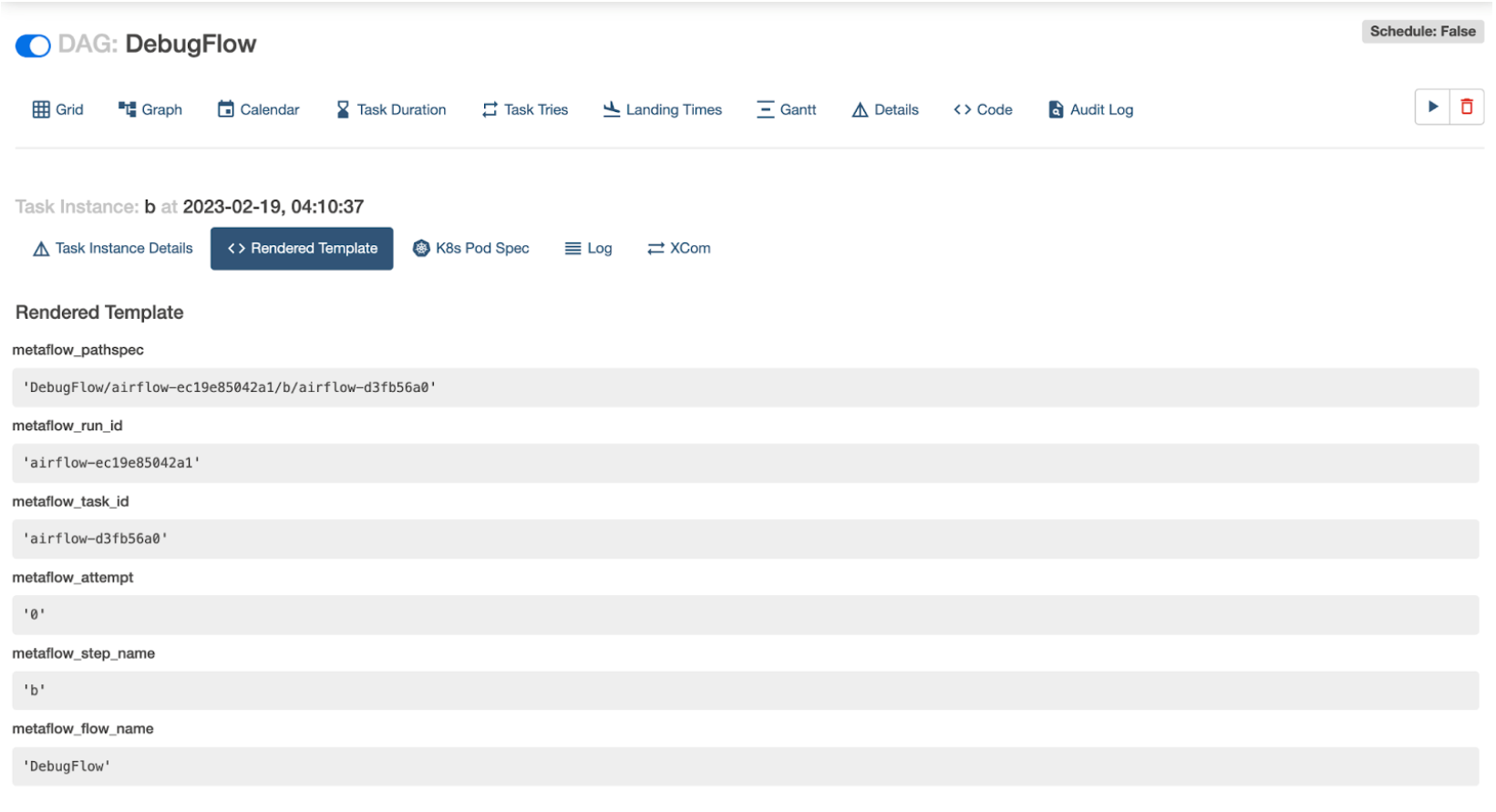
Next, we want to reproduce the above error locally. We do this by resuming the specific Airflow run that failed:
python debug.py resume --origin-run-id airflow-ec19e85042a1
This will reuse the results of the start and a step from the Airflow run. It will try to
rerun the step b locally, which fails with the same error as it does in production.
You can fix the error locally, as above. In the case of this simple flow, you can run the whole flow locally to confirm that the fix works. After validating the results, you would deploy a new version to production with airflow create.
However, this might not be a feasible approach for complex production flow. For instance, the flow might process large amounts of data that can not be handled in your local instance. We have better approaches for staging flows for production:
Staging flows for production
The easiest approach to test a demanding flow is to run it on Kubernetes. This works even with resume:
python debug.py resume --origin-run-id airflow-ec19e85042a1 --with kubernetes
This will resume your flow and run every step on Kubernetes. When you are ready to test a fixed flow end-to-end, just run it as follows:
python debug.py run --with kubernetes
Alternatively, you can change the name of the flow temporarily, e.g. from DebugFlow to
DebugFlowStaging. Then you can run airflow create with the new name, which will create
a separate staging flow on Airflow. You can also use the
@project
decorator.
You can test the staging flow freely without interfering with the production flow. Once the staging flow runs successfully, you can confidently deploy a new version to production.