Creating Flows
This document introduces the basic concepts of Metaflow. If you are eager to try out Metaflow in practice, you can start with the tutorial. After the tutorial, you can return to this document to learn more about how Metaflow works.
The examples below show how to execute flows on the command line. If you want to develop flows in a notebook, take a quick look at how to run flows in a notebook.
The Structure of Metaflow Code
Metaflow follows the dataflow paradigm which models a program as a directed graph of operations. This is a natural paradigm for expressing data processing pipelines, machine learning in particular.
We call the graph of operations a flow. You define the operations, called steps, which are nodes of the graph and contain transitions to the next steps, which serve as edges.
Metaflow sets some constraints on the structure of the graph. For starters, every flow
needs a step called start and a step called end. An execution of the flow, which we
call a run, starts at start. The run is successful if the final end step
finishes successfully.
What happens between start and end is up to you. You can construct the graph in
between using an arbitrary combination of the following three types of transitions
supported by Metaflow:
Linear
The most basic type of transition is a linear transition. It moves from one step to another one.
Here is a graph with two linear transitions:
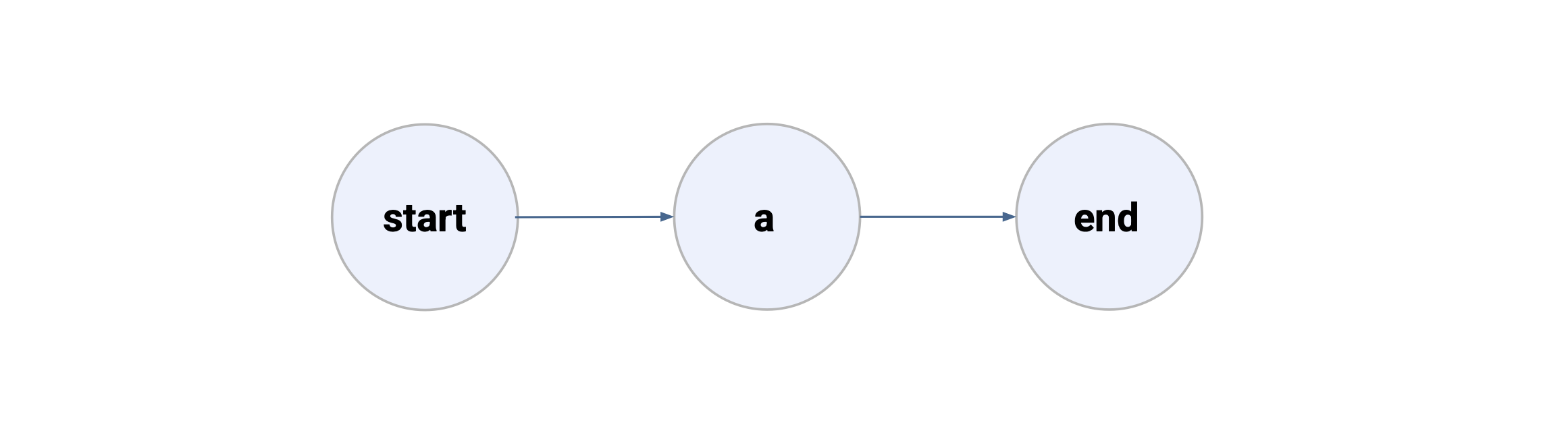
The corresponding Metaflow script looks like this:
from metaflow import FlowSpec, step
class LinearFlow(FlowSpec):
@step
def start(self):
self.my_var = 'hello world'
self.next(self.a)
@step
def a(self):
print('the data artifact is: %s' % self.my_var)
self.next(self.end)
@step
def end(self):
print('the data artifact is still: %s' % self.my_var)
if __name__ == '__main__':
LinearFlow()
Save this snippet to a file, linear.py. You can execute Metaflow flows on the command
line like any other Python scripts. Try this:
python linear.py run
Whenever you see a flow like this in the documentation, just save it in a file and execute it like above.
Artifacts
Besides executing the steps start, a, and end in order, this flow creates a data
artifact called my_var. In Metaflow, data artifacts are created simply by assigning
values to instance variables like my_var.
Artifacts are a core concept of Metaflow. They have a number of uses:
They allow you to manage the data flow through the flow without having to load and store data manually.
All artifacts are persisted so that they can be analyzed later using the Client API, visualized with Cards, and even used across flows.
Artifacts works consistently across environments, so you can run some steps locally and some steps in the cloud without having to worry about transferring data explicitly.
Having access to past artifacts greatly helps debugging, since you can eyeball data before failures and even resume past executions after fixing bugs.
Data artifacts are available in all steps after they have been created, so they behave as any normal instance variables. An exception to this rule are branches, as explained below.
Branch
You can express parallel steps with a branch. In the figure below, start
transitions to two parallel steps, a and b. Any number of parallel steps are
allowed. A benefit of a branch like this is performance: Metaflow can execute a and
b over multiple CPU cores or over multiple instances in the cloud.
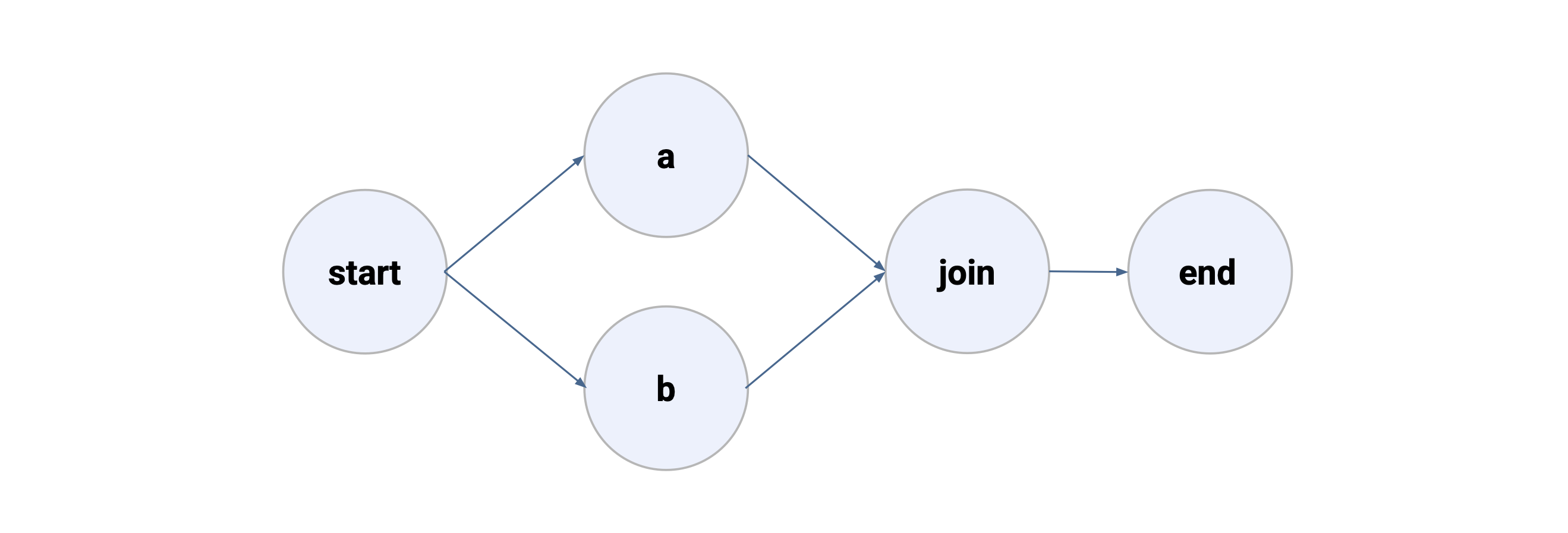
from metaflow import FlowSpec, step
class BranchFlow(FlowSpec):
@step
def start(self):
self.next(self.a, self.b)
@step
def a(self):
self.x = 1
self.next(self.join)
@step
def b(self):
self.x = 2
self.next(self.join)
@step
def join(self, inputs):
print('a is %s' % inputs.a.x)
print('b is %s' % inputs.b.x)
print('total is %d' % sum(input.x for input in inputs))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
BranchFlow()
Every branch must be joined. The join step does not need to be called join as above
but it must take an extra argument, like inputs above.
In the example above, the value of x above is ambiguous: a sets it to 1 and b to
2. To disambiguate the branches, the join step can refer to a specific step in the
branch, like inputs.a.x above. For convenience, you can also iterate over all steps in
the branch using inputs, as done in the last print statement in the above join step.
For more details, see the section about data flow through the
graph.
Note that you can nest branches arbitrarily, that is, you can branch inside a branch. Just remember to join all the branches that you create.
Foreach
Static branches like above are useful when you know the branches at the development time. Alternatively, you may want to branch based on data dynamically. This is the use case for a foreach branch.
Foreach works similarly like the branch above but instead of creating named step methods, many parallel copies of steps inside a foreach loop are executed.
A foreach loop can iterate over any list like titles below.
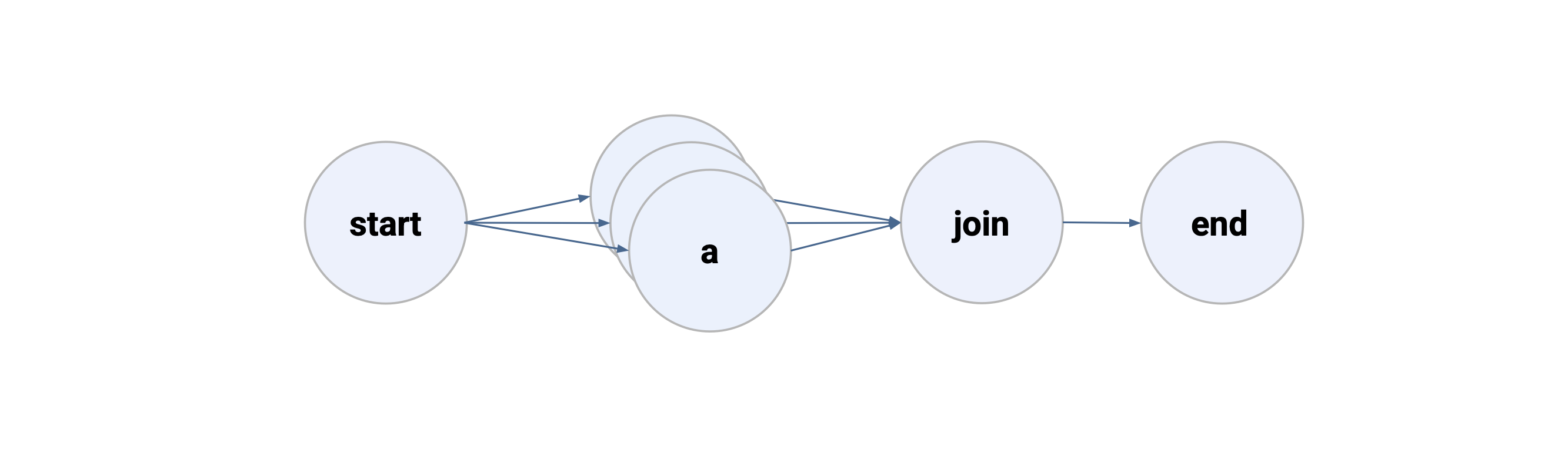
from metaflow import FlowSpec, step
class ForeachFlow(FlowSpec):
@step
def start(self):
self.titles = ['Stranger Things',
'House of Cards',
'Narcos']
self.next(self.a, foreach='titles')
@step
def a(self):
self.title = '%s processed' % self.input
self.next(self.join)
@step
def join(self, inputs):
self.results = [input.title for input in inputs]
self.next(self.end)
@step
def end(self):
print('\n'.join(self.results))
if __name__ == '__main__':
ForeachFlow()
The foreach loop is initialized by specifying a keyword argument foreach in
self.next(). The foreach argument takes a string that is the name of a list stored
in an instance variable, like titles above.
Steps inside a foreach loop create separate tasks to process each item of the list.
Here, Metaflow creates three parallel tasks for the step a to process the three items
of the titles list in parallel. You can access the specific item assigned to a task
with an instance variable called input.
Foreach loops must be joined like static branches. Note that tasks inside a foreach loop
are not named, so you can only iterate over them with inputs. If you want, you can
assign a value to an instance variable in a foreach step which helps you to identify the
task.
You can nest foreaches and combine them with branches and linear steps arbitrarily.
Conditionals
This is a new feature in Metaflow 2.18.
Conditional branches allow you to choose one branch among multiple
options, based on the value of an artifact. Similar to foreach, you
pass a condition keyword argument to self.next, pointing to an artifact
that determines which branch to follow. Unlike regular branches, where
multiple paths can run in parallel, conditional branching ensures that
exactly one branch is executed.

Specify the candidate branches as a Python dictionary, similar to a
switch statement in many languages. Dictionary keys can be any valid type
(e.g. strings, integers, booleans), and the values must be valid @step methods.
The keys may be specified
via a Config file,
e.g. {cfg.first_choice: self.head}. Note that you must specify a key for
every possible value of the condition artifact.
This flow flips a coin and executes a heads or tails branch accordingly:
from metaflow import FlowSpec, step
import random
class CoinFlipFlow(FlowSpec):
@step
def start(self):
self.choice = random.choice(['head', 'tails'])
self.next({"head": self.head, "tails": self.tails}, condition='choice')
@step
def head(self):
print('Head!')
self.next(self.end)
@step
def tails(self):
print('Tails!')
self.next(self.end)
@step
def end(self):
print("This is the end")
if __name__ == '__main__':
CoinFlipFlow()
Note that you don't need a join step with conditionals, since only one branch is execution so there are no multiple sets of artifacts to be merged.
Recursion
This is a new feature in Metaflow 2.18.
While Metaflow doesn't support arbitrary loops across the flow - the flows are Directed Acyclic Graphs after all - as a special case, you can execute a single step multiple times recursively.
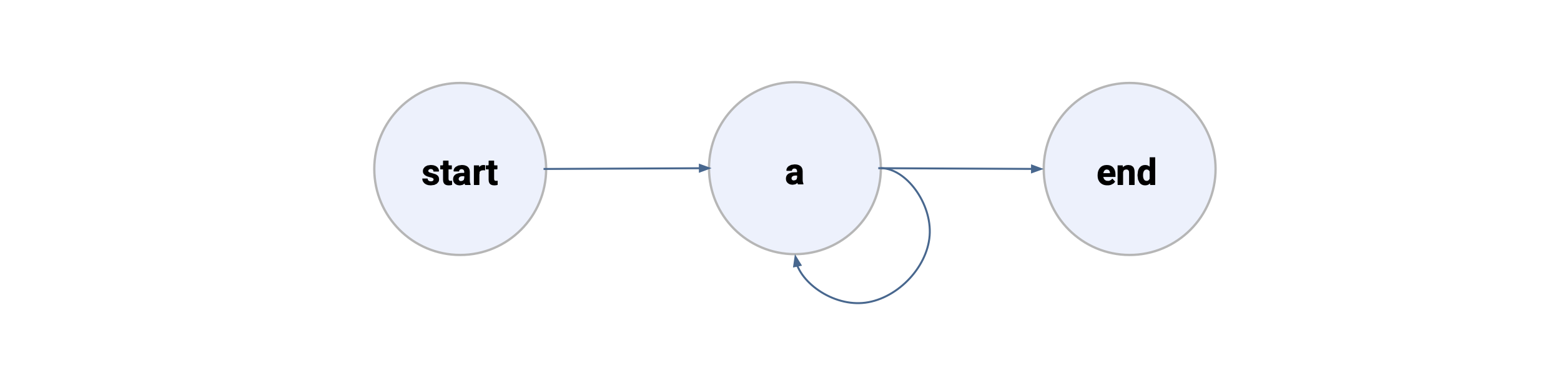
Similar to foreach, this construct causes a single step to spawn multiple tasks,
each producing its own artifacts. Recursion is particularly useful when you want
to snapshot and persist artifacts before continuing processing.
If the flow
fails during recursion, you can use the
resume command to pick up
from the latest successful iteration instead of starting over. And, you are able
to use the Client API to inspect any iteration afterwards -
for instance, a particular parametrization of a hyperparameter optimization loop.
Define recursion simply by creating a conditional where one of the branches points
at the step itself. For instance, the example below implements the
following while loop
x = 1
while x < 5:
x += 1
...as the loop step:
from metaflow import FlowSpec, step
class WhileFlow(FlowSpec):
@step
def start(self):
self.next(self.loop)
@step
def loop(self):
self.x = getattr(self, 'x', 0) + 1
print('X is', self.x)
self.again = self.x < 5
self.next({True: self.loop, False: self.end}, condition='again')
@step
def end(self):
print("The final X is", self.x)
if __name__ == '__main__':
WhileFlow()
You can interrupt the flow mid-execution and try python while.py resume to observe
how the execution resumes from the latest successful iteration instead of starting
again.
Nesting constructs
You can combine and nest the above constructs almost arbitrarily.
For example, the following flow orchestrates multiple agents working in
parallel using a foreach.
The agent state is persisted through recursive steps, and the agent can
continue along a suitable path through a conditional.

What should be a step?
There is not a single right way of structuring code as a graph of steps but here are some best practices that you can follow.
Metaflow treats steps as indivisible units of execution. That is, a step either succeeds or fails as a whole. After the step has finished successfully, Metaflow persists all instance variables that were created in the step code, so the step does not have to be executed again even if a subsequent step fails. In other words, you can inspect data artifacts that were present when the step finished, but you can not inspect data that were manipulated within a step.
This makes a step a checkpoint. The more granular your steps are, the more control you have over inspecting results and resuming failed runs.
A downside of making steps too granular is that checkpointing adds some overhead. It would not make sense to execute each line of code as a separate step. Keep your steps small but not too small. A good rule of thumb is that a single step should not take more than an hour to run, preferably much less than that.
Another important consideration is the readability of your code. Try running
python myflow.py show
which prints out the steps of your flow. Does the overview give you a good idea of your code? If the steps are too broad, it might make sense to split them up just to make the overall flow more descriptive.
How to define parameters for flows?
Here is an example of a flow that defines a parameter, alpha:
from metaflow import FlowSpec, Parameter, step
class ParameterFlow(FlowSpec):
alpha = Parameter('alpha',
help='Learning rate',
default=0.01)
@step
def start(self):
print('alpha is %f' % self.alpha)
self.next(self.end)
@step
def end(self):
print('alpha is still %f' % self.alpha)
if __name__ == '__main__':
ParameterFlow()
Parameters are defined by assigning a Parameter object to a class variable. Parameter
variables are automatically available in all steps, like alpha above.
You can set the parameter values on the command line as follows:
python parameter_flow.py run --alpha 0.6
You can see available parameters with:
python parameter_flow.py run --help
Parameters are typed based on the type of their default value. If there is no meaningful default for a parameter, you can define it as follows:
num_components = Parameter('num_components',
help='Number of components',
required=True,
type=int)
Now the flow can not be run without setting --num_components to an integer value.
See the API reference for the Parameter class for more
information.
Advanced parameters
For even more versatile ways to configure flows, take a look at Configuring Flows.
In the example above, Parameters took simple scalar values, such as integers or
floating point values. To support more complex values for Parameter, Metaflow allows
you to specify the value as JSON. This feature comes in handy if your Parameter is a
list of values, a mapping, or a more complex data structure.
This example allows the user to define a GDP by country mapping as a Parameter:
from metaflow import FlowSpec, Parameter, step, JSONType
class JSONParameterFlow(FlowSpec):
gdp = Parameter('gdp',
help='Country-GDP Mapping',
type=JSONType,
default='{"US": 1939}')
country = Parameter('country',
help='Choose a country',
default='US')
@step
def start(self):
print('The GDP of %s is $%dB' % (self.country, self.gdp[self.country]))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
JSONParameterFlow()
Execute the code as follows:
python parameter_flow.py run --gdp '{"US": 1}'
Data flow through the graph
As previously mentioned, for linear steps, data artifacts are propagated and any linear step can access data artifacts created by previous steps using instance variables. In this case, Metaflow can easily determine the value of each artifact by simply taking the value of that artifact at the end of the previous step.
In a join step, however, the value of artifacts can potentially be set to different values on the incoming branches; the value of the artifact is said to be ambiguous.
To make it easier to implement a join step after foreach or branch, Metaflow provides a
utility function, merge_artifacts, to aid in propagating unambiguous values.
from metaflow import FlowSpec, step
class MergeArtifactsFlow(FlowSpec):
@step
def start(self):
self.pass_down = 'a'
self.next(self.a, self.b)
@step
def a(self):
self.common = 5
self.x = 1
self.y = 3
self.from_a = 6
self.next(self.join)
@step
def b(self):
self.common = 5
self.x = 2
self.y = 4
self.next(self.join)
@step
def join(self, inputs):
self.x = inputs.a.x
self.merge_artifacts(inputs, exclude=['y'])
print('x is %s' % self.x)
print('pass_down is %s' % self.pass_down)
print('common is %d' % self.common)
print('from_a is %d' % self.from_a)
self.next(self.c)
@step
def c(self):
self.next(self.d, self.e)
@step
def d(self):
self.conflicting = 7
self.next(self.join2)
@step
def e(self):
self.conflicting = 8
self.next(self.join2)
@step
def join2(self, inputs):
self.merge_artifacts(inputs, include=['pass_down', 'common'])
print('Only pass_down and common exist here')
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
MergeArtifactsFlow()
In the example above, the merge_artifacts function behaves as follows:
- in
join,pass_downis propagated because it is unmodified in bothaandb. - in
join,commonis also propagated because it is set to the same value in both branches. Remember that it is the value of the artifact that matters when determining whether an artifact is ambiguous; Metaflow uses content based deduplication to store artifacts and can therefore determine if the value of two artifacts is the same. - in
join,xis handled by the code explicitly prior to the call tomerge_artifactswhich causesmerge_artifactsto ignorexwhen propagating artifacts. This pattern allows you to manually resolve any ambiguity in artifacts you would like to see propagated. - in
join,yis not propagated because it is listed in theexcludelist. This pattern allows you to prevent the propagation of artifacts that are no longer relevant. Remember that the default behavior ofmerge_artifactsis to propagate all incoming artifacts. - in
join,from_ais propagated because it is only set in one branch and therefore is unambiguous.merge_artifactswill propagate all values even if they are present on only one incoming branch. - In
join2, theincludekeyword is used and allows you to explicitly specify the artifacts to consider when merging. This is useful when the list of artifacts to exclude is larger than the one to include. You cannot use both anincludeandexcludelist in the samemerge_artifactscall. Note also that if an artifact is specified ininclude, an error will be thrown if it either doesn't exist in the current step or doesn't exist on one of the inputs (in other words, it is "missing"). Theincludeparameter is only available in version 2.2.1 or later.
The merge_artifacts function will raise an exception if an artifact that it should
merge has an ambiguous value. Remember that merge_artifacts will attempt to merge all
incoming artifacts except if they are already present in the step or have been
explicitly excluded in the exclude list.