Organizing Results
A boring, under-appreciated part of high-quality science (or any project work in general), is keeping results organized. This is the key to effective collaboration, versioning of parallel lines of work, and reproducibility.
The good news is that Metaflow does 80% of this work for you without you having to do anything. This document explains how Metaflow keeps things organized with a concept called namespaces and how you can optionally make results even neater with tags.
Namespaces
As explained in Creating Flows, Metaflow persists all runs and all
the data artifacts they produce. Every run gets a unique run ID, e.g. HelloFlow/546,
which can be used to refer to a specific set of results. You can access these results
with the Client API.
Many users can use Metaflow concurrently. Imagine that Anne and Will are collaborating
on a project that consists of two flows, PredictionFlow and FeatureFlow. As they,
amongst other people, run their versions independently they end up with the following
runs:
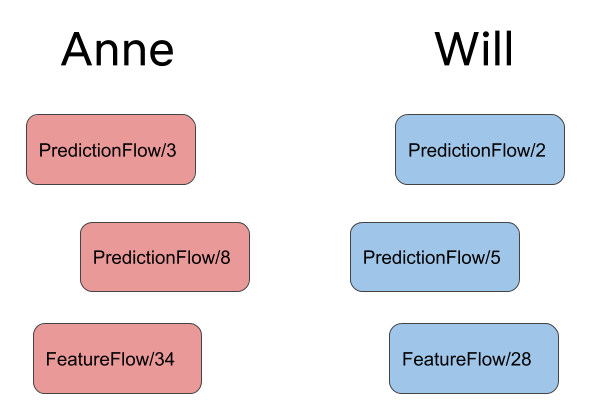
Anne could analyze her latest PredictionFlow results in a notebook by remembering that
her latest run is PredictionFlow/8. Fortunately, Metaflow makes this even easier
thanks to namespaces:
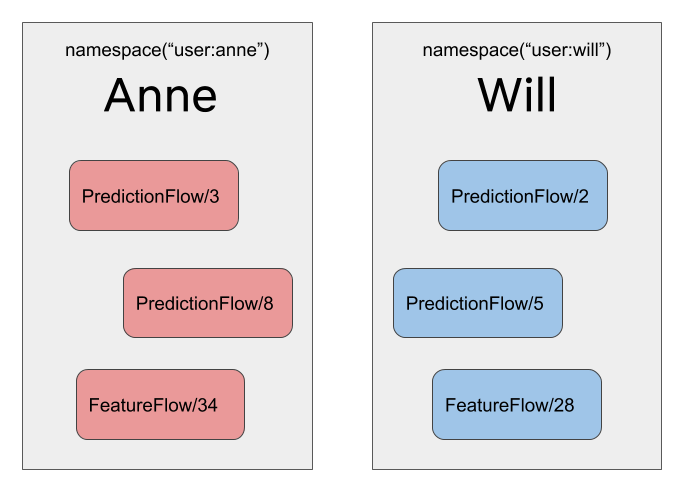
When Anne runs PredictionFlow, her runs are automatically tagged with her
username, prefixed with user:. By default, when Anne uses the Client
API in a notebook or in a Python script, the API only returns results
that are tagged with user:anne. Instead of having to remember the exact ID of her
latest run, she can simply say:
from metaflow import Flow
run = Flow('PredictionFlow').latest_run
For Anne, this will return 'PredictionFlow/8'. For Will, this will return
'PredictionFlow/5'.
Switching Namespaces
Namespaces are not about security or access control. They help you to keep results organized. During development, organizing results by the user who produced them is a sensible default.
You can freely explore results produced by other people. In a notebook (for example), Anne can write
from metaflow import Flow, namespace
namespace('user:will')
run = Flow('PredictionFlow').latest_run
to see Will's latest results, in this case, 'PredictionFlow/5'.
You can also access a specific run given its ID directly:
from metaflow import Flow, namespace
run = Run('PredictionFlow/5')
However, this will fail for Anne, since PredictionFlow/5 is in Will's namespace. An
important feature of namespaces is to make sure that you can't accidentally use someone
else's results, which could lead to hard-to-debug, incorrect analyses.
If Anne wants to access Will's results, she must do so explicitly by switching to Will's namespace:
from metaflow import Flow, namespace
namespace('user:will')
run = Run('PredictionFlow/5')
In other words, you can use the Client API freely without having to worry about using incorrect results by accident.
If you use the Client API in your flows to access results of other flows, you can use
the --namespace flag on the command line to switch between namespaces. This is a
better approach than hardcoding a namespace() function call in the code that defines
your Metaflow workflow.
Global Namespace
What if you know a run ID, but you don't know whose namespace it belongs to? No worries, you can access all results in the Metaflow universe in the global namespace:
from metaflow import Flow, namespace
namespace(None)
run = Run('PredictionFlow/5')
Setting namespace(None) allows you to access all results without limitations. Be
careful though: relative references like latest_run make little sense in the global
namespace since anyone can produce a new run at any time.
Production Namespaces
During development, namespacing by the username feels natural. However, when you schedule your flow to run automatically, runs are not related to a specific user anymore. It is typical for multiple people to collaborate on a project that has a canonical production version. It is not obvious which user "owns" the production version.
Moreover, it is critical that you, and all other people, can keep experimenting on the
project without having to worry about breaking the production version. If the production
flow ran in the namespace of any individual, relative references like latest_run could
break the production easily as the user keeps executing experimental runs.
As a solution, by default the production namespace is made separate from the usernamespace:
-9e825aaf633bd9c3557c35b34291c647.png)
Isolated production namespaces have three main benefits:
- Production tokens allow all users of Metaflow to experiment freely with any project without having to worry about accidentally breaking a production deployment. Even if they ran step-functions create, they could not overwrite a production version without explicit consent, via a shared production token, by the person who did the previous authorized deployment.
- An isolated production namespace makes it easy to keep production results separate from any experimental runs of the same project running concurrently. You can rest assured that when you switch to a production namespace, you will see only results related to production - nothing more, nothing less.
- By having control over the production namespace, you can alter data that is seen by production flows. For instance, if you have separate training and prediction flows in production, the prediction flow can access the previously built model as long as one exists in the same namespace. By changing the production namespace, you can make sure that a new deployment isn't tainted by old results.
If you are a single developer working on a new project, you don't have to do anything
special to deal with production namespaces. You can rely on the default behavior of
step-functions create.
Production tokens
When you deploy a Flow to production for the first time, Metaflow creates a new, isolated production namespace for your production flow. This namespace is identified by a production token, which is a random identifier that identifies a production deployment, e.g. production:PredictionFlow3 above. You can examine production results in a notebook by switching to the production namespace.
If another person wants to deploy a new version of the flow to production, they must use the same production token. You, or whoever has the token, are responsible for sharing it with users who are authorized to deploy new versions to production. This manual step should prevent random users from deploying versions to production inadvertently.
After you have shared the production token with another person, they can deploy a new version on AWS Step Functions with
python production_flow.py step-functions create --authorize TOKEN_YOU_SHARED_WITH_THEM
or on Argo Workflows with
python production_flow.py argo-workflows create --authorize TOKEN_YOU_SHARED_WITH_THEM
or on Airflow with
python production_flow.py airflow create --authorize TOKEN_YOU_SHARED_WITH_THEM
They need to use the --authorize option only once. Metaflow stores the token for them
after the first deployment, so they need to do this only once.
Resetting a production namespace
If you call step-functions create (or argo-workflow create) again, it will deploy an
updated version of your code in the existing production namespace of the flow.
Sometimes the code has changed so drastically that you want to recreate a fresh namespace for its results. You can do this as follows for AWS Step Functions:
python production_flow.py step-functions create --generate-new-token
and equivalently for Argo Workflows:
python production_flow.py argo-workflows create --generate-new-token
or Airflow:
python production_flow.py airflow create --generate-new-token
This will deploy a new version in production using a fresh, empty namespace.
Resuming across namespaces
The resume command is smart
enough to work across production and personal namespaces. You can resume a production
workflow without having to do anything special with namespaces.
You can resume runs of other users, and you can resume any production runs. The results of your resumed runs are always created in your personal namespace.
Tagging
The user: tag is assigned by Metaflow automatically. In addition to automatically
assigned tags, you can add and remove arbitrary tags in objects. Tags are an excellent
way to add extra annotations to runs, tasks etc., which makes it easier for you and
other people to find and retrieve results of interest.
If you know a tag to be attached before a run starts, you can add it using the run
--tag command line option. You can add multiple tags with multiple --tag options. For
instance, this will annotate a HelloFlow run with a tag crazy_test.
python helloworld.py run --tag crazy_test
Often, you may want to add or change tags after a run has completed. In contrast to artifacts, tags can be mutated any time: Consider them as mutating interpretations of immutable (arti)facts. You can mutate tags either using the Client API or the command line.
Add a tag on the command line like this:
python helloworld.py tag add --run-id 2 crazy_test
Remove works symmetrically:
python helloworld.py tag remove --run-id 2 crazy_test
You can see the current set of tags with
python helloworld.py tag list
Note that the above command lists also system tags that can not be mutated, but they can be used for filtering.
Filtering by tags
You can access runs (or steps or tasks) with a certain tag easily using the Client API:
from metaflow import Flow
run = list(Flow('HelloFlow').runs('crazy_test'))[0]
This will return the latest run of HelloFlow with a tag crazy_test in your
namespace. Filtering is performed both based on the current namespace() and the tag
filter.
You can also filter by multiple tags:
from metaflow import Flow
run = list(Flow('HelloFlow').runs('crazy_test', 'date:20180301'))[0]
This requires that all the tags listed, and the current namespace, are present in the object.
You can see the set of tags assigned to an object with the .tags property. In the
above case, run.tags would return a set with a string crazy_test amongst other
automatically assigned tags.
Tags as Namespaces
Let's consider again the earlier example with Anne and Will. They are working on their
own versions of PredictionFlow but they want to collaborate on FeatureFlow. They
could add a descriptive tag, say xyz_features, to FeatureFlow runs.
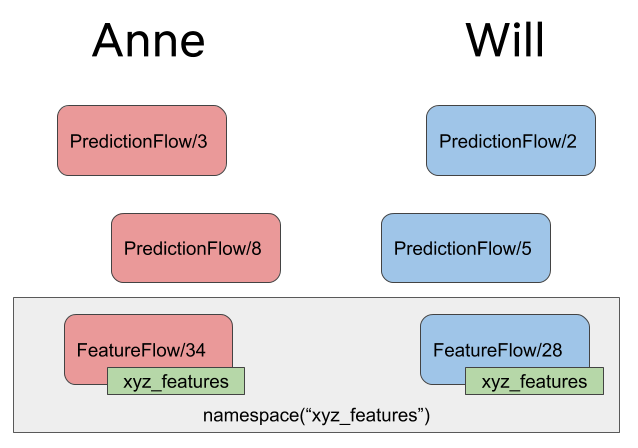
Now, they can easily get the latest results of FeatureFlow regardless of the user who
ran the flow:
from metaflow import Flow
namespace('xyz_features')
run = Flow('FeatureFlow').latest_run
This will return FeatureFlow/34 which happened to be run by Anne. If Will runs the
flow again, his results will be the latest results in this namespace.
We encourage you to use a combination of namespaces, domain-specific tags, and filtering by tags to design a workflow that works well for your project.
Accessing Current IDs in a Flow
This section contains an overview of current. For a complete API, see the API
reference for current.
Tagging and namespaces, together with the Client API, are the main ways for accessing results of past runs. Metaflow uses these mechanisms to organize and isolate results automatically, so in most cases you don't have to do anything.
However, in some cases you may need to deal with IDs explicitly. For instance, if your flow interacts with external systems, it is a good idea to inform the external system about the identity of the run, so you can trace back any issues to a specific run. Also IDs can come in handy if you need to version externally stored data.
For this purpose, Metaflow provides a singleton object current that represents the
identity of the currently running task. Use it in your FlowSpec to retrieve current
IDs of interest:
from metaflow import FlowSpec, step, current
class CurrentFlow(FlowSpec):
@step
def start(self):
print("flow name: %s" % current.flow_name)
print("run id: %s" % current.run_id)
print("origin run id: %s" % current.origin_run_id)
print("step name: %s" % current.step_name)
print("task id: %s" % current.task_id)
print("pathspec: %s" % current.pathspec)
print("namespace: %s" % current.namespace)
print("username: %s" % current.username)
print("flow parameters: %s" % str(current.parameter_names))
self.next(self.end)
@step
def end(self):
print("end has a different step name: %s" % current.step_name)
print("end has a different task id: %s" % current.task_id)
print("end has a different pathspec: %s" % current.pathspec)
if __name__ == '__main__':
CurrentFlow()
In particular, the value of current.pathspec is convenient as an unambiguous
identifier of a task. For instance, the above script printed out
pathspec: CurrentFlow/1/start/550539
Now you can inspect this particular task using the Client API by
instantiating a Task object as follows:
from metaflow import Task
task = Task('CurrentFlow/1/start/550539')
print task.stdout
This prints out the output of the task identified by the pathspec.
The current singleton also provides programmatic access to the CLI option
--origin-run-id used by the
resume within your flow code.
If a user explicitly overrides the CLI option --origin-run-id, the current singleton
would reflect that value.
If not, it would be the id of the last invocation of run (successful or not).
This value would remain the same even after multiple successful resume invocations. If
you don't want this behavior, you can always override the CLI option origin-run-id and
resume a specific run.
For regular run invocations, the value of current.origin_run_id is None.
Suppose we invoked resume for the above script to re-run everything from start
without explicitly overriding the CLI option origin-run-id, we can see the value
chosen by Metaflow using the current singleton:
python current_flow.py resume start
You should see the origin_run_id used by the resume in the output (the exact value
for you might be different):
origin run id: 4