Checkpointing Progress
Metaflow artifacts are used to persist models, dataframes, and other Python objects upon task completion. They
checkpoint the flow's state at step boundaries, enabling you to inspect results of a task with
the Client API and resume execution from any
step.
In some cases, a task may require a long time to execute. For example, training a model on an expensive GPU instance (or across a cluster) may take several hours or even days. In such situations, persisting the final model only upon task completion is not sufficient. Instead, it is advisable to checkpoint progress periodically while the task is executing, so you won’t lose hours of work in the event of a failure.
You can use a Metaflow extension, metaflow-checkpoint, to create and use in-task checkpoints easily: Just add
@checkpoint and call current.checkpoint.save to checkpoint progress periodically. A major benefit of @checkpoint
is that it keeps checkpoints organized automatically alongside Metaflow tasks, so you don’t have to deal with saving,
loading, organizing, and keeping track of checkpoint files manually.
Notably, @checkpoint integrates seamlessly with popular AI and ML frameworks such as XGBoost, PyTorch, and others, as
described below. For more background, read the announcement blog post for
@checkpoint.
The @checkpoint decorator is not a built-in part of core Metaflow yet, so you have to install it separately as
described below. Also its APIs may change in the future, in contrast to the APIs of core Metaflow which are
guaranteed to stay backwards compatible. Please share your feedback on
Metaflow Slack!
Installing @checkpoint
To use the @checkpoint extension, install it with
pip install metaflow-checkpoint
in the environments where you develop and deploy Metaflow code. Metaflow packages extensions for remote execution automatically, so you don’t need to include it in container images used to run tasks remotely.
Using @checkpoint
The @checkpoint decorator operates by persisting files in a local directory to the Metaflow datastore. This makes it
directly compatible with many popular ML and AI frameworks that support persisting checkpoints on disk natively.
Let’s demonstrate the functionality with this simple flow that tries to increment a counter in a loop that fails 20% of
the time. Thanks to @checkpoint and @retry, the flaky_count step recovers from exceptions and continues counting
from the latest checkpoint, succeeding eventually:
import os
import random
from metaflow import FlowSpec, current, step, retry, checkpoint
class CheckpointCounterFlow(FlowSpec):
@step
def start(self):
self.counter = 0
self.next(self.flaky_count)
@checkpoint
@retry
@step
def flaky_count(self):
cp_path = os.path.join(current.checkpoint.directory, "counter")
def _save_counter():
print(f"Checkpointing counter value {self.counter}")
with open(cp_path, "w") as f:
f.write(str(self.counter))
self.latest_checkpoint = current.checkpoint.save()
def _load_counter():
if current.checkpoint.is_loaded:
with open(cp_path) as f:
self.counter = int(f.read())
print(f"Checkpoint loaded!")
_load_counter()
print("Counter is now", self.counter)
while self.counter < 10:
self.counter += 1
if self.counter % 2 == 0:
_save_counter()
if random.random() < 0.2:
raise Exception("Bad luck! Try again!")
self.next(self.end)
@step
def end(self):
print("Final counter", self.counter)
if __name__ == "__main__":
CheckpointCounterFlow()
After installing the metaflow-checkpoint extension, you can run the flow as usual:
python checkpoint_counter.py run
The flow demonstrates typical usage of @checkpoint:
@checkpointinitializes a temporary directory,current.checkpoint.directory, which you can use as a staging area for data to be checkpointed.By default,
@checkpointloads the latest task-specific checkpoint in the directory automatically. If a checkpoint is found,current.checkpoint.is_loadedis set toTrue, so you can initialize processing with previously stored data, like loading the latest value ofcounterin this case.Periodically during processing, you can save any data required to resume processing in the staging directory and call
current.checkpoint.save()to persist it in the datastore.We save a reference to the latest checkpoint in an artifact,
latest_checkpoint, which allows us to find and load particular checkpoints later, as explained later in this document.
Behind the scenes, besides loading and storing data efficiently, @checkpoint takes care of scoping the checkpoint data to specific tasks. You can use @checkpoint in many parallel tasks, even in a foreach, knowing that @checkpoint will automatically load checkpoints specific to each branch. It also makes it possible to use checkpoints across runs, as described in Deciding what checkpoint to use.
Observing @checkpoint through cards
Try running the above flow with the default Metaflow
@card:
python checkpoint_counter.py run --with card
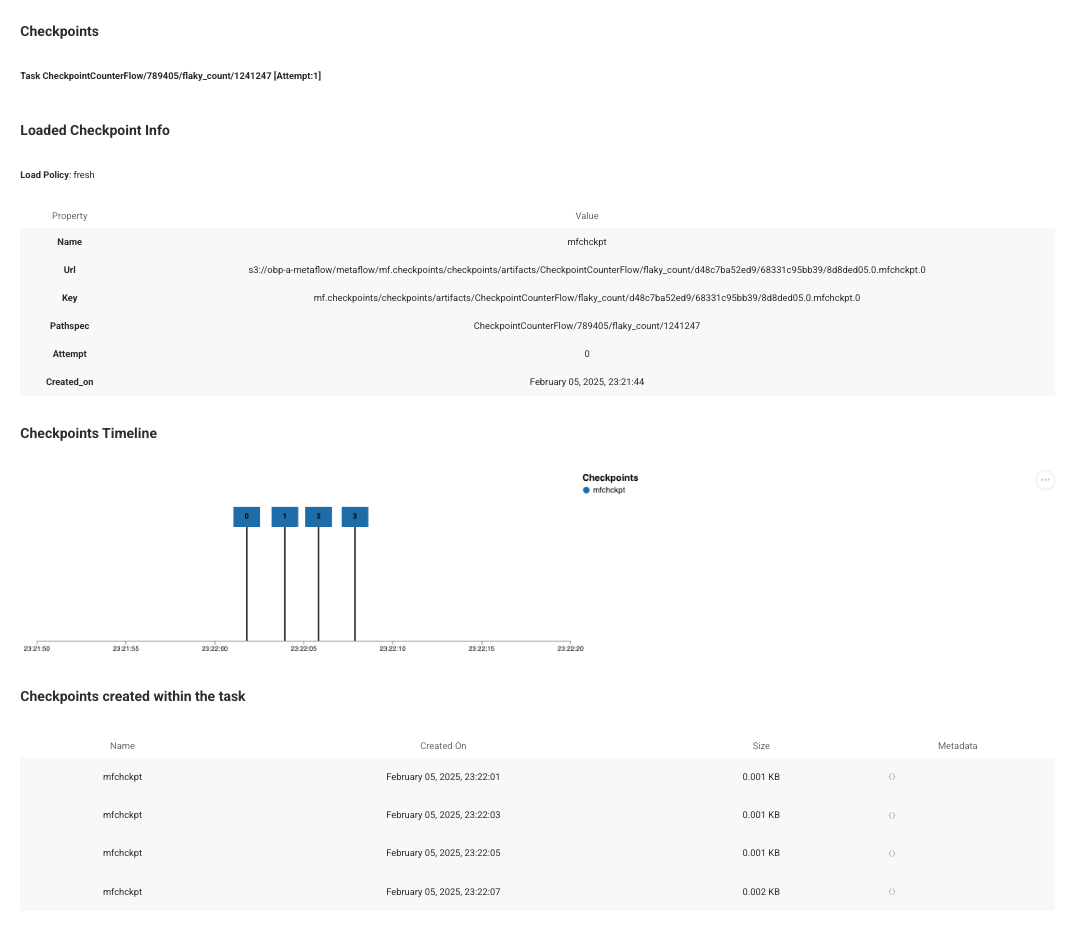
If a step decorated with @checkpoint has a card enabled, it will add information about checkpoints loaded and stored in the card. For instance, the screenshot below shows a card associated with the second attempt ([Attempt: 1] at the top of the card) which loaded a checkpoint produced by the first attempt and stored four checkpoints at 2 second intervals: