Selecting a Checkpoint to Use
By default, @checkpoint is scoped to a single task, allowing you to recover from a previous checkpoint using @retry.
This behavior is desirable when implementing a step that must preserve progress in case of unexpected interruptions or
retries. When initiating a new run, any existing checkpoints are disregarded to avoid accidentally loading stale or
incorrect checkpoints.
At times, it is useful to reuse checkpoints across different runs or even leverage checkpoints created by another
workflow, such as one trained by a colleague. The @checkpoint decorator enables this functionality by allowing you to
configure checkpoint loading behavior using the load_policy argument.
The decorator supports three distinct load policies, as depicted below:
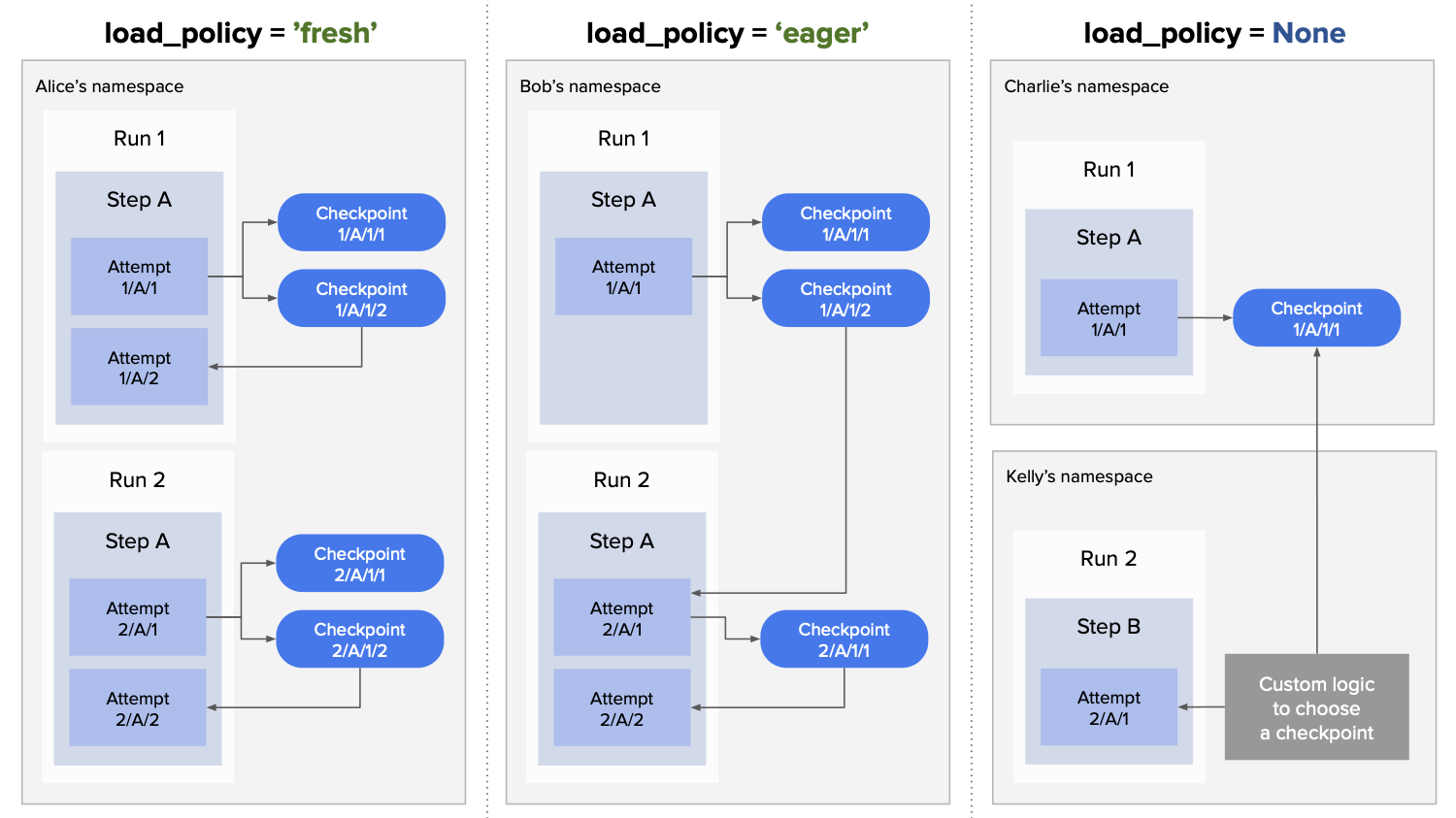
Let’s cover the policies from left to right:
load_policy='fresh' - retry tasks without losing progress
This is the default policy. Checkpoints are scoped to a task: The latest available task-specific checkpoint is loaded
automatically upon @retry. Checkpoints are not loaded across runs. This behavior is often desirable in deployed
flows, which should be able to recover from unexpected failures while remaining isolated from any other concurrent
runs.
Checkpoints are scoped to a task based on the flow name, step name, and foreach index. This ensures that you can
use @checkpoint in foreach tasks, e.g. when running a hyperparameter search, training multiple models in parallel.
Each model gets a dedicated set of checkpoints without interference from concurrent tasks.
load_policy='eager' - make progress incrementally across runs
The eager policy is well suited for iterative development: It allows you to interrupt a run and resume it later in
another run, preserving progress made within a task. For instance, you can train a model for a few epochs, interrupt
training, change code, and use the resume command to resume training from the latest checkpoint.
Test this by changing @checkpoint to @checkpoint(load_policy=’eager’) in our earlier CheckpointCounterFlow
example. Run the flow, interrupt a flaky_count step after a
while, and try python checkpoint_counter.py resume flaky_count You’ll notice that flaky_count will load an
existing checkpoint. If the step has run to completion earlier, the latest checkpoint allows you to skip processing
altogether. If you modify the code and want to ignore past stale checkpoints, simply change the checkpoint back to
@checkpoint(load_policy=’fresh’).
Note that eager mode operates within the current namespace. That is, it will only consider checkpoints created by you, not those created by your colleagues. This is deliberate as we want to ensure that multiple people can work concurrently with deterministic results. If you want to load checkpoints across namespaces, the next load policy will come in handy.
load_policy=None - choose your own policy
If the fresh and eager policies don’t work for your needs, you can take control of what checkpoints are loaded and when
by setting load_policy=None. In this case, no checkpoints are loaded automatically. Instead, you are expected to
implement custom logic that chooses what checkpoint to load.
It is a useful pattern to store a reference to the latest checkpoint - returned by save() - in an artifact which
allows you to find specific checkpoints using the Client API. This makes it easy to implement
robust custom policies for loading checkpoints produced by specific flows and deployments, while staying organized with
the lineage of checkpoints.
This example illustrates the idea, loading a checkpoint produced by the above CheckpointCounterFlow:
import os
from metaflow import FlowSpec, current, step, retry, checkpoint, Flow, namespace
class CounterPolicyFlow(FlowSpec):
@checkpoint(load_policy=None)
@step
def start(self):
namespace(None)
run = Flow('CheckpointCounterFlow').latest_successful_run
print(f"Accessing checkpoints from run {run.pathspec}")
cp = run['flaky_count'].task['latest_checkpoint'].data
current.checkpoint.load(cp)
with open(os.path.join(current.checkpoint.directory, 'counter')) as f:
self.counter = int(f.read())
self.next(self.end)
@step
def end(self):
print("Loaded counter", self.counter)
if __name__ == "__main__":
CounterPolicyFlow()
This flow refers to the latest successful execution of CheckpointCounterFlow across all namespaces, thanks to
namespace(None), allowing it to pick the latest checkpoint produced by any
production deployment or a colleague who has run the flow. It finds a reference to the latest checkpoint through the
latest_checkpoint artifact and loads it by passing it as an argument to current.checkpoint.load.
Listing checkpoints
Imagine the following scenario: You have deployed a long-running training run in production which takes days to complete. While training is making progress, you want to load a checkpoint produced by it into another flow, e.g. to test the model-in-progress. As the training task hasn't finished, we can’t access the checkpoint through an artifact as we did in the snippet above, since artifacts are only persisted upon task completion,
You can use current.checkpoint.list(task=Task) to list checkpoints associated with a task, even a currently running
one. To see this in action, you can alter CounterPolicyFlow to use list to find the latest checkpoint from the
flaky_count step, which may or may not have completed:
namespace(None)
run = Flow('CheckpointCounterFlow').latest_run
cp = current.checkpoint.list(task=run['flaky_count'].task)[0]
current.checkpoint.load(cp)
The list call returns all checkpoints produced by the task, so you are not limited to selecting the latest one. You
can even compare progress across checkpoints by loading each one of them separately.
Loading checkpoints outside flows
You can load checkpoints outside flows, e.g. in a notebook. You can import a Checkpoint object and use it as a context manager, similar to current.checkpoint:
import os
from metaflow import Checkpoint, Flow
with Checkpoint() as cp:
run = Flow('CheckpointCounterFlow').latest_run
latest = cp.list(task=run['flaky_count'].task)[0]
cp.load(latest)
with open(os.path.join(cp.directory, 'counter')) as f:
print(f.read())
To load a checkpoint, simply pass a reference to an existing checkpoint to Checkpoint.load.
When used as a context manager, Checkpoint will take care of creating and cleaning up a temporary directory for loading checkpoint data automatically.