Config-Driven Experimentation
Usually, a Config determines how a run should behave. It is also possible to use configs, in
conjunction with a configuration manager such as Hydra, to use configs to define
what should be run.
Hydra enables you to define and generate configuration sets that parameterize an entire suite of
Metaflow runs. By using configs, you can easily set up experiments and (hyper)parameter sweeps.
With the help of Metaflow's Runner and Deployer APIs, these runs
can be executed automatically.
This section gives two examples demonstrating the idea in practice:
A benchmark template that allows you to choose what to run on the command line (source).
A large-scale parameter sweep with real-time monitoring (source).
Clone the examples from the source repository and follow along.
You can run ordinary hyperparameter sweeps easily using
foreach. The examples in this section
cover a more advanced case where you need to alter flow-level behavior, decorators in particular,
in experiments. Start with foreach and come back here if it
isn't sufficient for your needs.
Benchmark: A templatized flow with pluggable modules
Consider the following common scenario: You want to compare the performance of various implementations across a common test setup. It should be easy to add new solutions without having to modify the benchmarking setup itself.
Our example
demonstrates the idea by measuring the performance of a simple dataframe operation -
grouping by hour - across three dataframe backends, Pandas, Polars, and DuckDB. Adding
a new backend is easy: Simply drop a module in the backend
directory
with a config file that specifies the dependencies needed.
Thanks to Config, the shared benchmark flow,
ConfigurableBenchmark, can modify its @pypi to match the requirements of the chosen backend, importing
the backend module on the
fly.
Besides Hydra, this pattern of pluggable modules, imported on the fly with custom dependencies is useful in various applications. You can use it for pluggable feature encoders, models etc.
Running with Hydra
Imagine you want to compare the performance of the backends. You could run
ConfigurableBenchmark three times, choosing a suitable config manually but as the number of
backends increases, this can become tedious.
Managing experiments like this is where Hydra shines. We implement a simple Hydra
app
which uses the Metaflow Runner to launch and manage a run.
We can then use the versatile syntax of Hydra to choose which experiments to run, letting Hydra
take care of merging each backend-specific config with a global
config
automatically.
The resulting setup looks like this:
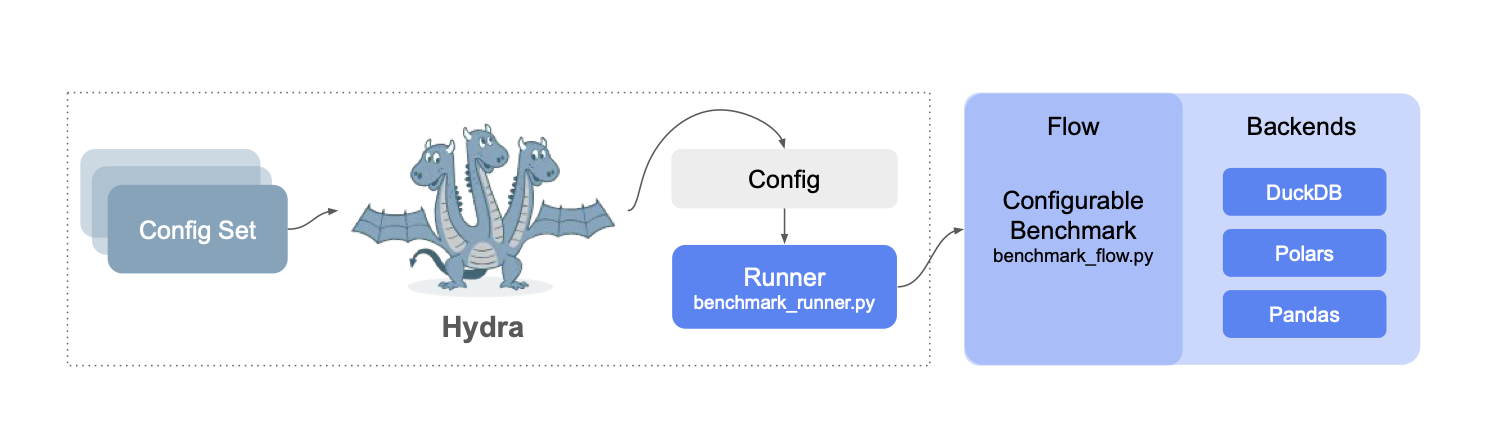
As experiments are managed by Hydra, instead of running a flow directly, we launch them via the Hydra app. For instance, we can test a specific backend like this:
python bechmark_runner.py +backend=pandas
Take a look at the documentation of Hydra for details about its rich syntax for configuring experiments. In particular, we can use Hydra to run multiple experiments using its Multirun mode. We can use it to test all backends sequentially:
python bechmark_runner.py +backend=pandas,polars,duckdb -m
The runner assigns a unique Metaflow tag in a set of experiments, making it easy to focus and fetch results of a Hydra run. You can see the command in action here (spoiler: DuckDB is fast!):
Note that the default
configuration
includes a remote: batch key, which runs the experiments using @batch. You can remove the
remote line to execute the tests locally, or you can change it to kubernetes.
Sweep: Orchestrating and observing experiments at scale
The benchmark example above relied on a finite set of manually defined configurations, one for each
backend. In contrast, this example,
hydra-sweep,
generates a set of configurations on the fly, sweeping over a grid of quantitative parameters.
Typically, you would use a foreach to sweep over a parameter grid, but if the experiments
require changes in decorators, Hydra comes in handy again, thanks to its native support for
sweeping over experiments.
Since the parameter grid can be large, it is not convenient to run experiments sequentially as with hydra-benchmark.
While we could parallelize experiments in a limited fashion on our local workstation, a more robust solution
for large-scale experimentation is to deploy experiments to one of the production
orchestrators supported by Metaflow, which allows us
to run hundreds of large-scale experiments in parallel.
We follow a similar pattern as with hydra-benchmark above, constructing a Hydra app,
sweep_deployer.py that
deploys flows using the Deployer API. We take extra care of
isolating deployments using @project branches,
so multiple sets of experiments can be run concurrently.
We attach a unique tag to all runs, which allows us to fetch all results for analysis and visualization.
This is done by
SweepAnalyticsFlow
which updates its results automatically through a @trigger every time an experiment finishes successfully.
The setup looks like this:
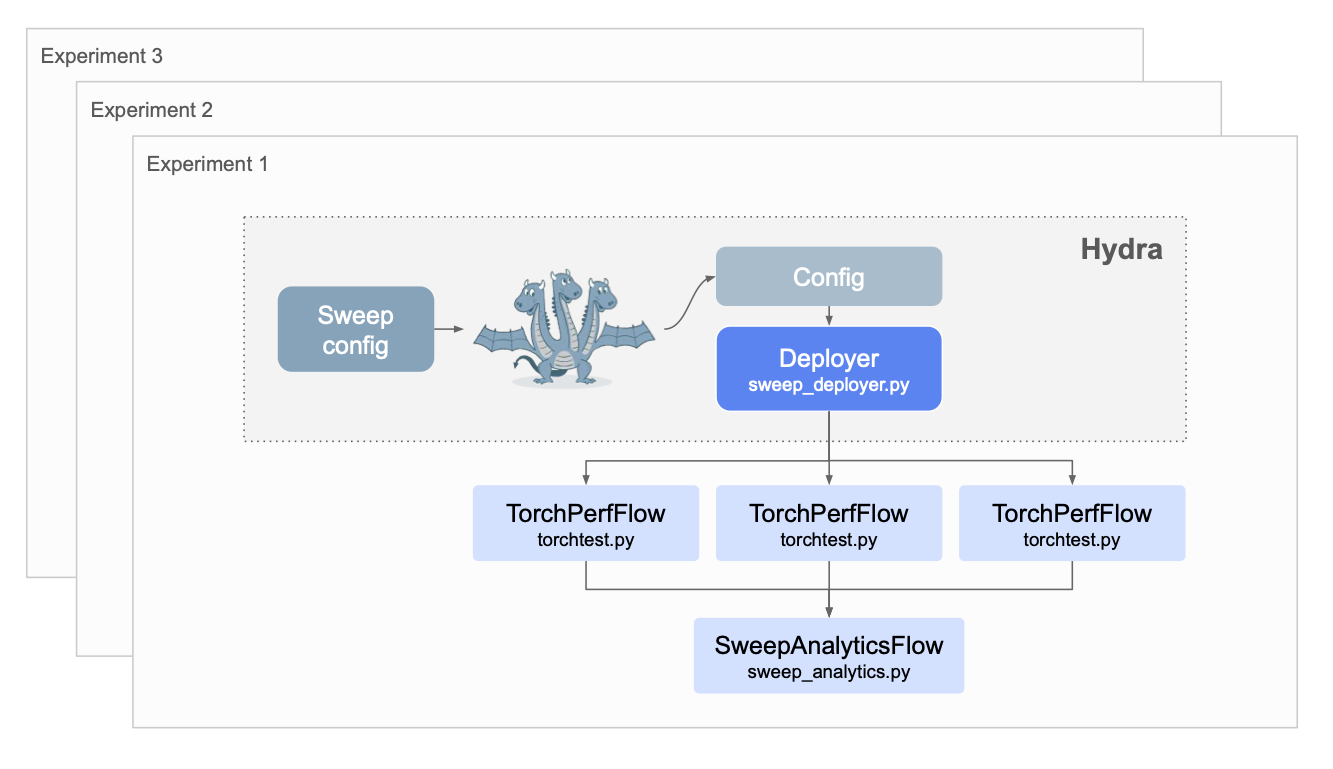
This pattern is applicable to any experiment that requires sweeping over configurations. To demonstrate the
idea in practice, we use a flow,
TorchPerfFlow, to
test the performance of PyTorch doing a matrix squaring operation on a varying number of CPU cores, over
a varying dimensionality of the matrix - the sweep over these parameters is defined in this Hydra
config.
We adjust the @resources(cpu=) setting through the config, which wouldn't be doable
using a normal foreach.
You can start the sweep, assuming you have Metaflow configured to work with Argo Workflows, by executing
python sweep_deployer.py -m
It will start by deploying SweepAnalyticsFlow, followed by each individual TorchPerfTest experiment
which will produce statistics in real-time. As shown in the screen recording below, you can observe results
through SweepAnalyticsFlow that updates every time new data points appear: