Using GPUs and Other Accelerators
Metaflow enables access to hardware-accelerated computing, GPUs in particular, when using AWS Batch or Kubernetes. You can leverage
- Single accelerators - e.g.
@resources(gpu=1) - Single instances with multiple accelerators - e.g.
@resources(gpu=4) - Multiple instances with multiple accelerators
You can find many examples of how to use Metaflow to fine-tune LLMs and other generative AI models, as well as how to train computer vision and other deep learning models in these articles.
Using accelerators
Before you can start taking advantage of hardware-accelerated steps, you need to take care of two prerequisites:
Add hardware-accelerated instances in your Metaflow stack. Take a look specific tips for AWS Batch and Kubernetes.
Configure your flow to include necessary drivers and frameworks.
After this, using the accelerators in straightforward as explained below.
Don't hesitate to reach out to Metaflow Slack if you need help get started!
GPUs
To use GPUs in your compute environment, use the
@resources decorator to get quick access to one or more GPUs
like in this example:
from metaflow import FlowSpec, step, resources
class GPUFlow(FlowSpec):
@resources(memory=32000, cpu=4, gpu=1)
@step
def start(self):
from my_script import my_gpu_routine
my_gpu_routine()
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
GPUFlow()
As usual with @resources, the decorator is ignored for local runs. This allows you to
develop the code locally, e.g. using GPU resources on your local workstation. To get access
to the requested resources in the cloud, run the flow --with kubernetes or --with batch.
If you need more fine-grained control over what GPUs get used, use the decorators
specific to compute environment: For instance, @kubernetes allows you to
specify a gpu_vendor and @batch allows you to
specify a queue targeting a compute environment containing
specific GPUs. For more information, see guidance for AWS Batch and Kubernetes.
Using AWS Trainium and Inferentia
On AWS, you can use AWS-specific hardware accelerators, Trainium and Inferentia. For more details, see a blog post outlining them in the context of Metaflow.
When using AWS Batch, you can request the accelerators simply by defining the number
of Trainium or Inferentia cores in @batch:
@batch(trainium=16)@batch(inferentia=16)
Note that Metaflow supports distributed training over multiple
Trainium instances. For detailed instructions, visit
the metaflow-trainium repository.
Contact Metaflow Slack if you are interested in using Trainium
of Inferentia with @kubernetes.
Using Google's Tensor Processing Units (TPUs)
Contact Metaflow Slack if you are interested in using TPUs with Metaflow in the Google cloud.
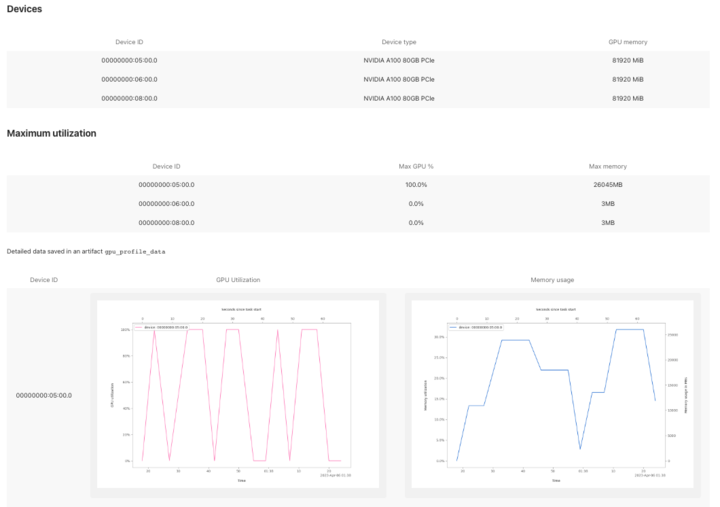
Monitoring GPU utilization
To monitor GPU devices and their utilization, add a custom card
@gpu_profile in your GPU steps.