Internals of Dependency Management
Behind the scenes, Metaflow does much more than just wrapping CLI commands such as
pip install or conda install:
- It creates isolated virtual environments for every step on the fly, automatically, caching them for future use.
- It supports pinning of the
pythoninterpreter version whichpipdoesn't support natively. - It resolves the full dependency graph of every step, locking the graph for stability and reproducibility, storing the metadata for auditing.
- It ships the locally resolved environment for remote execution, even when the remote environment uses a different operating system and CPU architecture than the client (OS X vs. Linux).
- It snapshots all packages in the datastore, making it possible to rehydrate
environments in even thousands of parallel containers, which would cause
hiccups with parallel
pip installs.
For even more features, see Netflix's Metaflow
Extensions which contain even
more featureful @pypi and @conda.
How @pypi and @conda work
Here's what happens under the hood when you specify --environment=pypi or
--environment=conda. Both the options work the same way, as illustrated by
this diagram:
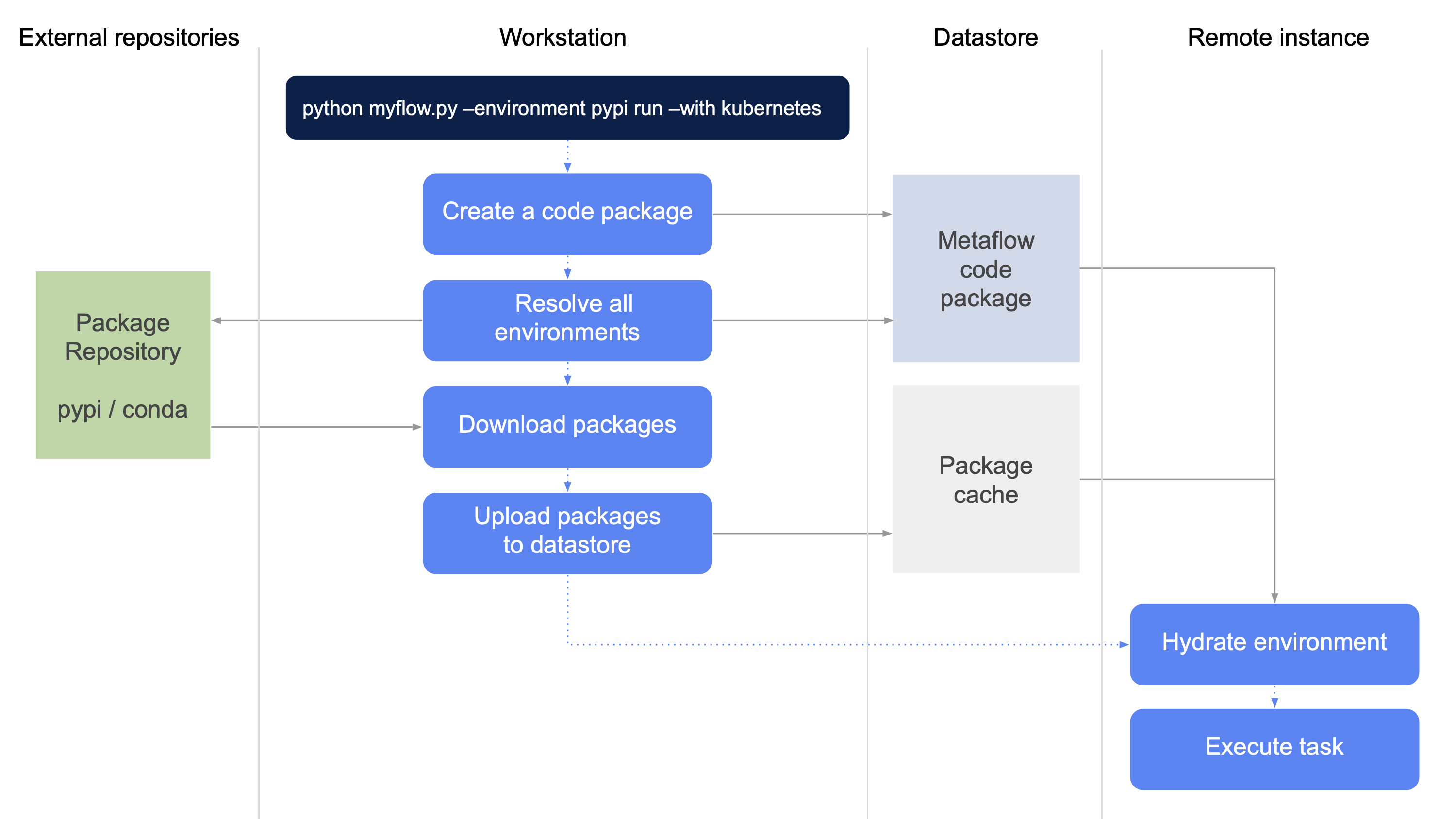
Let's go over the operation following the blue steps, starting at the top:
Local
.pyfiles and others specified by--package-suffixesare packaged in a code package as usual.When using
@pypior@conda, every step gets its own virtual environment.- If two steps have the same exact set of packages, the environment is reused across the steps.
- The environment is created using
mambaand the desired version ofpythonis installed. - For step-specific dependency resolution,
@pypiinvokespip, whereas@condausesmamba. - The full list of exact packages aka "a lockfile" is stored in the code package corresponding to a run or a deployment.
Once a full list of packages has been created for each step, packages are downloaded in parallel and stored locally.
The packages are uploaded in the Metaflow datastore, e.g. S3 in the case of AWS-based configuration. This ensures that remote tasks won't need to download packages repeatedly and redundantly from an upstream package repository.
This completes operations on the client side. The code package together with the cached packages in the datastore contain a complete, isolated environment for each step which is needed to execute its tasks.
Runtime operation
When @pypi / @conda -enabled tasks execute remotely, we start by
setting up an empty virtual environment with mamba, download the
cached packages from the datastore, and unpack them in the environment.
The code package is unpacked to make local dependencies available.
After this, the task is executed in an environment that contains exactly the specified packages. Nothing more, nothing less.