Technical Overview
Make sure you have read Basics of Metaflow before diving into technical details below. You can find more technical details at the infrastructure level in Administrator's Guide to Metaflow. This document focuses on the Metaflow codebase.
We wanted to build a data science platform that can make data science code usable, scalable, reproducible, and production-ready, as described in the Why Metaflow section. There are many ways to achieve these high-level goals. We took an approach designed around the following four core functions:
- Provide a highly usable API for structuring the code as a workflow, i.e. as a directed graph of steps (usability).
- Persist an immutable snapshot of data, code, and external dependencies required to execute each step (reproducibility).
- Facilitate execution of the steps in various environments, from development to production (scalability, production-readiness).
- Record metadata about previous executions and make them easily accessible (usability, reproducibility).
This document gives an overview of how the core functionality is implemented.
Architecture
Here is a high-level architecture diagram of Metaflow:
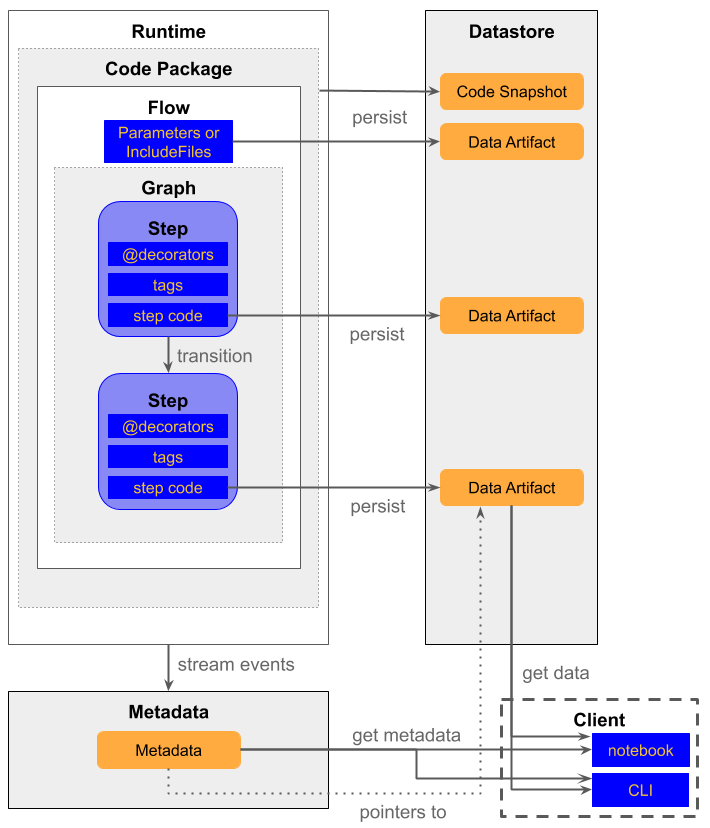
Below, we will describe the components in detail. To highlight the time-dimension which is missing from the diagram, we group the descriptions by the following phases in the development lifecycle:
- Development-time, i.e. when the code gets written.
- Runtime, i.e. when the code gets run.
- Result-time, i.e. when the results of the run get used.
Every component includes links to source files where the functionality is implemented.
Development-Time Components
The core development-time concept in Metaflow is a flow. It represents the business logic of what needs to be computed.
How to intertwine the business logic with the framework in the most usable manner is a central design concern of Metaflow. We want to encourage the user to structure the code in a way that enables reproducibility and scalability.
In contrast, we would like to minimize concerns related to production-readiness during development time. Optimally, the user can write idiomatic Python code focusing on the logic itself and the guard rails of the framework will automatically make the code production-ready.
Flow
A flow is the smallest unit of computation that can be scheduled for execution. Typically, a flow defines a workflow that pulls data from an external source as input, processes it in several steps, and produces output data.
User implements a flow by subclassing FlowSpec and implementing steps as methods.
Besides steps, a flow can define other attributes relevant for scheduling, such as
parameters and data triggers.
Graph
Metaflow infers a directed (typically acyclic) graph based on the transitions between step functions.
Metaflow requires the transitions to be defined so that the graph can be parsed from the source code of the flow statically. This makes it possible to translate the graph for execution by runtimes that support only statically defined graphs, such as Meson.
Step
A step is the smallest resumable unit of computation. It is implemented by the user as a
method that is decorated with the @step decorator in a flow class.
A step is a checkpoint. Metaflow takes a snapshot of the data produced by a step which in turn is used as input to the subsequent steps. Hence, if a step fails, it can be resumed without rerunning the preceding steps.
Being able to resume execution is a powerful feature. It would be convenient to be able to resume execution at any arbitrary line of code. The main reason why checkpointing is done at the step level instead of line level is the overhead of saving state. The user is encouraged to keep the steps small but not so small that the overhead becomes noticeable.
Decorators
The behavior of a step can be modified with decorators. Tags are the main mechanism for extending Metaflow. For instance, a decorator can catch exceptions, implement a timeout, or define resource requirements for a step.
A step may have arbitrary many decorators, implemented as Python decorators.
decorators.py- base class for decoratorsplugins- see various plugins for actual decorator implementations
Step Code
Step code is the body of a step. It implements the actual business logic of flow.
It is possible to implement various language bindings, e.g. R, for Metaflow so that only the language of the step code is changed while all the core functionality, implemented in Python, stays intact.
All instance variables, e.g. self.x, used in the step code become data artifacts
that are persisted automatically. Stack variables, e.g. x, are not persisted. This
dichotomy allows the user to control the overhead of checkpointing by explicitly
choosing between persistent vs. non-persistent variables in the step code.
Runtime Components
The core runtime concept in Metaflow is a run, that is, an execution of a user-defined
flow. A run happens when the user executes python myflow.py run on the command line.
A key design decision of Metaflow is to make the framework runtime-agnostic. The same code should be runnable in various environments, such as on a laptop during development or on a production-ready workflow orchestrator during production.
Similarly, we want to provide seamless scalability by allowing the same code run on a laptop in parallel over multiple processes or in the cloud over multiple batch jobs.
Task
The runtime counterpart of a step is a task. In runtime, a normal step spawns one task for execution. A foreach split step may spawn multiple tasks which are identified by a unique foreach stack.
Code Package
In order to be able to reproduce the results of a run, we need to snapshot the code that was run.
Code package is an immutable snapshot of the relevant code in the working directory, stored in the datastore, at the time when the run was started. A convenient side effect of the snapshot is that it also works as a code distribution mechanism for runs that happen in the cloud.
Environment
Unfortunately, just snapshotting the working directory of the flow code is not sufficient for reproducibility. The code often depends on external libraries which also need to be included in the snapshot.
The concept of an environment is closely related to code packages. The environment encapsulates both the flow code and its external dependencies, so that the exact execution environment can be reproduced on a remote system accurately.
Runtime
A run of a flow is executed by executing tasks defined by steps in a topological order. It is the job of a runtime to orchestrate this execution. A better name for "runtime" might be a scheduler.
For quick local iterations, Metaflow comes with a built-in runtime which executes tasks as separate processes. However, this is not intended as a production-grade scheduler.
For production runs, one should use a runtime that supports retries, error reporting, logging, is highly available, scalable, and preferably comes with a user-friendly UI. At Netflix, Meson is such a runtime. It is well-supported by Metaflow.
A key feature of Metaflow is that it is agnostic of the runtime. The same code can be executed both with the local runtime and with production runtime, which enables a rapid development-deploy-debug cycle.
Datastore
Metaflow requires an object store where both code snapshots and data artifacts can be persisted. This data store should be accessible by all environments where Metaflow code is executed. The AWS S3 is a perfect solution for this need. Secondarily, Metaflow supports using a local disk as a data store, which is mainly useful during the development of Metaflow itself.
An important feature of Metaflow is that the data store is used as a content-addressed storage. Both code and data are identified by a hash of their contents, similar to Git. So equal copies of data are deduplicated automatically. Note that this deduplication is limited in scope however; data across different flows will not be deduplicated.
Metadata Provider
A centralized Metadata Provider keeps track of runs. Strictly speaking, this functionality is not required by Metaflow, but it makes the system much more usable. The service also helps to make data artifacts and other metadata about runs more discoverable during result-time, as explained below.
metadata.py- base class for metadata providersservice.py- default implementation of the metadata providerlocal.py- local implementation of the metadata provider
Result-time Components
Flows are defined and run for their results. Metaflow supports a number of different ways to consume outputs of runs: Results can be written to Hive tables for consumption by downstream systems and dashboards, they can be accessed in a notebook for further analysis, or in a hosted web service (this last functionality is not yet available in Open Source).
Metaflow Client
Metaflow provides a highly usable Python API to access results of previous runs,
called metaflow.client. A typical way to use metaflow.client is to access data
artifacts of past runs in a Jupyter notebook. It is extremely convenient to be able to
examine the internal state of production runs or perform further ad-hoc analysis of the
results in a notebook.